
Page 17 - 2025S
P. 17
10 UEC Int’l Mini-Conference No.54
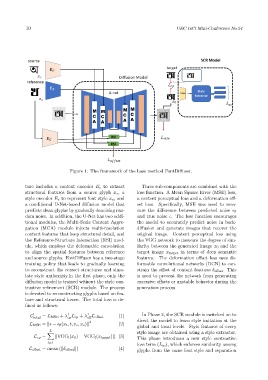
Figure 1: The framework of the base method FontDiffuser.
ture includes a content encoder E c to extract Three sub-components are combined with the
structural features from a source glyph x c , a loss function. A Mean Square Error (MSE) loss,
style encoder E s to represent font style x s , and a content perceptual loss and a deformation off-
a conditional U-Net-based diffusion model that set loss. Specifically, MSE was used to mea-
predicts clean glyphs by gradually denoising ran- sure the difference between predicted noise ϵ θ
dom noise. In addition, the U-Net has two addi- and true noise ϵ. The loss function encourages
tional modules, the Multi-Scale Content Aggre- the model to accurately predict noise in back-
gation (MCA) module injects multi-resolution diffusion and generate images that recover the
content features that keep structural detail, and original image. Content perceptual loss using
the Reference-Structure Interaction (RSI) mod- the VGG network to measure the degree of sim-
ule, which employs the deformable convolution ilarity between the generated image x 0 and the
to align the spatial features between reference target image x target in terms of deep semantic
and source glyphs. FontDiffuser has a two-stage features. The deformation offset loss uses de-
training policy that leads to gradually learning formable convolutional networks (DCN) to con-
to reconstruct the correct structures and simu- strain the offset of content features δ offset . This
late style uniformity.In the first phase, only the is used to prevent the network from generating
diffusion model is trained without the style con- excessive offsets or unstable behavior during the
trastive refinement (SCR) module. The process generation process.
is devoted to reconstructing glyphs based on fea-
ture and structural losses. The total loss is de-
fined as follows:
1 1 1 In Phase 2, the SCR module is switched on to
L total = L MSE + λ L cp + λ L offset (1)
cp
off
2 direct the model to learn style imitation at the
L MSE = ∥ϵ − ϵ θ (x t , t, x c , x s )∥ (2)
global and local levels. Style features of every
L
X style image are obtained using a style extractor.
L cp = ∥VGG l (x 0 ) − VGG l (x target )∥ (3) This phase introduces a new style contrastive
l=1 loss term (L sc ), which enforces similarity among
L offset = mean (∥δ offset ∥) (4) glyphs from the same font style and separation