
Page 35 - 2024S
P. 35
28 UEC Int’l Mini-Conference No.52
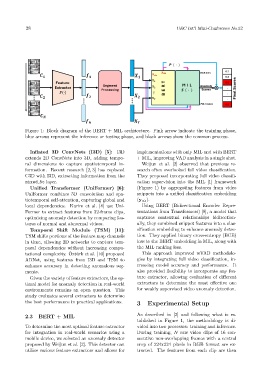
Figure 1: Block diagram of the BERT + MIL architecture. Pink arrow indicate the training phase,
blue arrows represent the inference or testing phase, and black arrows show the common process.
Inflated 3D ConvNets (I3D) [5]: I3D implementations with only MIL and with BERT
extends 2D ConvNets into 3D, adding tempo- + MIL, improving VAD analysis in a single shot.
ral dimensions to capture spatiotemporal in- Weijun et al. [2] observed that previous re-
formation. Recent research [2, 3] has replaced search often overlooked full video classification.
C3D with I3D, extracting information from the They proposed incorporating full video classifi-
mixed 5c layer. cation supervision into the MIL [1] framework
Unified Transformer (UniFormer) [6]: (Figure 1) by aggregating features from video
UniFormer combines 3D convolution and spa- snippets into a unified classification embedding
tiotemporal self-attention, capturing global and (y cls ).
local dependencies. Karim et al. [4] use Uni- Using BERT (Bidirectional Encoder Repre-
Former to extract features from 32-frame clips, sentations from Transformers) [8], a model that
optimizing anomaly detection by comparing fea- captures contextual relationships bidirection-
tures of normal and abnormal videos. ally, they combined snippet features into a clas-
Temporal Shift Module (TSM) [11]: sification embedding to enhance anomaly detec-
TSM shifts portions of the feature map channels tion. They applied binary cross-entropy (BCE)
in time, allowing 2D networks to capture tem- loss to the BERT embedding in MIL, along with
poral dependencies without increasing compu- the MIL ranking loss.
¨
tational complexity. Ozt¨urk et al. [10] proposed This approach improved wVAD methodolo-
ADNet, using features from I3D and TSM to gies by integrating full video classification, in-
enhance accuracy in detecting anomalous seg- creasing model accuracy and performance. It
ments. also provided flexibility to incorporate any fea-
Given the variety of feature extractors, the op- ture extractor, allowing evaluation of different
timal model for anomaly detection in real-world extractors to determine the most effective one
environments remains an open question. This for weakly supervised video anomaly detection.
study evaluates several extractors to determine
the best performance in practical applications. 3 Experimental Setup
2.3 BERT + MIL As described in [2] and following what is es-
tablished in Figure 1, the methodology is di-
To determine the most optimal feature extractor vided into two processes: training and inference.
for integration in real-world scenarios using a During training, N raw video clips of 16 con-
mobile device, we selected an anomaly detector secutive non-overlapping frames with a central
proposed by Weijun et al. [2]. This detector can crop of 224x224 pixels in RGB format are ex-
utilize various feature extractors and allows for tracted. The features from each clip are then